Monitoring with Prometheus, Loki, Grafana and Kubernetes. Part 1. Kubernetes cluster
All pages
| Name | Summary |
|---|---|
| Monitoring with Prometheus, Loki, Grafana and Kubernetes. Part 1. Kubernetes cluster | Here is about basic configuration of Kubernetes monitoring cluster |
| Monitoring with Prometheus, Loki, Grafana and Kubernetes. Part 2. SNMP | Here is about SNMP O_O |
| Monitoring with Prometheus, Loki, Grafana and Kubernetes. Part 3. GitLab Agent | How to connect a Kubernetes cluster to GitLab |
| Monitoring with Prometheus, Loki, Grafana and Kubernetes. Part 4. Prometheus exporters | Exporting Prometheus metrics |
| Monitoring with Prometheus, Loki, Grafana and Kubernetes. Part 5. kube-prometheus-stack | Migration to kube-prometheus-stack |
There is no specific purpose here, it is about service monitoring inside and outside the Kubernetes cluster. And in this part about basic configuration of Kubernetes monitoring cluster.
Kubernetes cluster
Kubernetes is a solution for creating a development, testing and production environment. I will build a kubernetes cluster on a desktop and use a minikube to create a Node. I’ll call it the development environment.
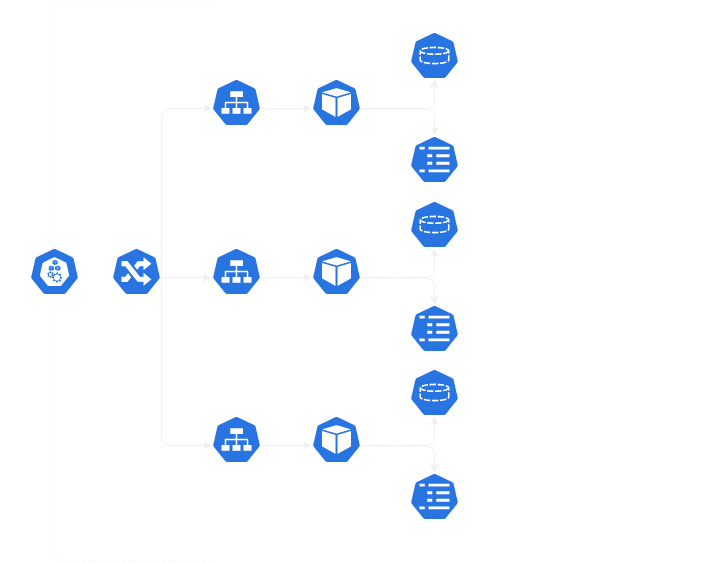
Why kubernetes?
Why Kubernetes? Container scaling? Yes, but for my simple cluster, it’s the convenience of configuration management and automation of updates.
Prometheus, Loki, Grafana integration into Kubernetes cluster
All configuration files can be taken from the repository.
Before creating Kubernetes objects for each image, you need to decide which data should be stored regardless of the Pod state. For Prometheus, there are prometheus.yml, prometheus_rules.yml configuration files and prometheus TSDB. For Grafana, there are prometheus.yaml, loki.yaml grafana datasources configuration files and grafana storage with grafana.db database (sqlite3 by default), alerting, plugins, csv, file-collections, png directories. For Loki, there are loki.yaml, loki_rules.yml loki configuration files and loki storage.
For configuration files in kubernetes there is a ConfigMap, for databases - Persistent Volumes
I will describe resources using classic Kubernetes manifests. I’m not gonna use Helm charts and Kubernetes Operators (for example, prometheus-operator) this time.
ConfigMap
I use ConfigMap to take the configuration outside of the image container and store it as a separate kubernetes object. At the same time, to update the configuration, it is enough to update the yaml file and restart the Pod in prometheus Deployment.
And here are my ConfigMap objects with comments:
Prometheus ConfigMap:
# prometheus-config-map.yaml
apiVersion: v1
# type of object
kind: ConfigMap
metadata:
# ConfigMap name
# used in the Deployment object template
name: prometheus-config
data:
# there are no scrape targets and alerting rules
prometheus.yml: |-
global:
scrape_interval: 15s
evaluation_interval: 15s
rule_files:
- /etc/prometheus/prometheus_rules.yml
prometheus_rules.yml: |-
Loki ConfigMap:
# loki-config-map.yaml
# loki parameters - https://grafana.com/docs/loki/latest/configuration/
apiVersion: v1
kind: ConfigMap
metadata:
name: loki-config
data:
loki.yaml: |-
auth_enabled: false
server:
http_listen_port: 3100
common:
path_prefix: /loki
storage:
filesystem:
chunks_directory: /loki/chunks
rules_directory: /loki/rules
replication_factor: 1
ring:
kvstore:
store: inmemory
schema_config:
configs:
- from: 2023-02-15
store: boltdb-shipper
object_store: filesystem
schema: v11
index:
prefix: index_
period: 24h
ruler:
storage:
type: local
local:
directory: /etc/loki/rules
rule_path: /tmp/loki/rules-temp
# there is no alertmanager in the cluster yet
alertmanager_url: http://localhost:9093
ring:
kvstore:
store: inmemory
enable_api: true
# see 'Grafana dashboard shows "too many outstanding requests"
# after upgrade to v2.4.2' issue
# https://github.com/grafana/loki/issues/5123
# and from docs:
# https://grafana.com/docs/loki/latest/configuration/#querier
# https://grafana.com/docs/loki/latest/configuration/#query_scheduler
querier:
max_concurrent: 2048
query_scheduler:
max_outstanding_requests_per_tenant: 2048
# loki-rules-config-map.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: loki-rules-config
data:
# there are no alerting rules
loki_rules.yml: |-
Grafana ConfigMap:
# grafana-config-datasources-map.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: grafana-config-datasources
labels:
version: "1"
data:
# 2 datasources: prometheus and loki
prometheus.yaml: |-
{
"apiVersion": 1,
"datasources": [
{
"access":"proxy",
"editable": true,
"name": "prometheus",
"orgId": 1,
"type": "prometheus",
"url": "http://prometheus-cluster-ip-service.default.svc.cluster.local:9090/prometheus/",
"version": 1
}
]
}
loki.yaml: |-
{
"apiVersion": 1,
"datasources": [
{
"access":"proxy",
"editable": true,
"name": "loki",
"orgId": 1,
"type": "loki",
"url": "http://loki-cluster-ip-service.default.svc.cluster.local:3100/",
"version": 1
}
]
}
PVC (Persistent Volume Claim)
If docker Volumes allows to mount a file system (directory on disk or in another container) from host machine into a container, then for kubernetes everything is somewhat different. There are Volumes (this is a Pod directory mounted inside each container from this Pod. Volume lifetime = Pod lifetime), Persistent Volumes or PV (this is a piece of storage in cluster, that have a lifecycle independent of any individual Pod that uses the PV) and Persistent Volume Claim or PVC (this is a request for PV storage with varying properties, size or access mode, as instance).
In my case, the PVC will use the default storageclass and the provisioner to get a local filesystem resource:
root@devbox:~$ kubectl get storageclass
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
standard (default) k8s.io/minikube-hostpath Delete Immediate false 127d
And here are my PVC objects with comments:
Prometheus PVC:
# prometheus-persistent-volume-claim.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
# PVC name
# use in template of Deployment object
name: prometheus-persistent-volume-claim
spec:
# see Access Modes -
# https://kubernetes.io/docs/concepts/storage/persistent-volumes/#access-modes
# 1Gi is just for testing in a small desktop cluster
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
Loki PVC:
# loki-persistent-volume-claim.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: loki-persistent-volume-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
Grafana PVC:
# grafana-persistent-volume-claim.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana-persistent-volume-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
Deployment
Deployment is an object that can contain either one or a group of Pods.
Pod is an object that can contain either one or a group of containers.
Why Deployment and not a Pod?
- The Deployment object allows you to flexibly change the fields in the configuration file, unlike the Pod object. For example, for an already created Pod, it is not possible to update
ports.containerPort, this will show an errorThe Pod "pod-name" is invalid: spec: Forbidden: pod updates may not change fields other than 'spec.containers[*].image', 'spec.initContainers[*].image', ... - Deployment monitors the status of each Pod. If the iPod is broken, restarts it
- Deployment is suitable for both development and production
And here are my Deployment objects with comments:
Prometheus Deployment:
# prometheus-deployment.yaml
apiVersion: apps/v1
# type of object
kind: Deployment
metadata:
# Deployment object name
name: prometheus-deployment
spec:
# number of Pods created based on the template below
replicas: 1
selector:
matchLabels:
component: prometheus
# configuration of each replica (each Pod) that will be created inside the Deployment object
template:
metadata:
labels:
# label is used to identify the Pod in the Deployment object,
# for example, to communicate with the Service ClusterIP object
# the label can be arbitrary
# there can be as many labels as you want
component: prometheus
spec:
volumes:
# define the available volumes
# for PVC and ConfigMap objects
- name: prometheus-config-volume
configMap:
name: prometheus-config
- name: prometheus-persistent-volume-claim
persistentVolumeClaim:
claimName: prometheus-persistent-volume-claim
containers:
- name: prometheus
image: prom/prometheus
# arguments when starting a container with Prometheus
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus/"
- "--web.external-url=https://localhost:9090/prometheus/"
ports:
# an opened port in a container with Prometheus
- containerPort: 9090
volumeMounts:
# mounting point of ConfigMap configuration files
# inside a Prometheus container
- name: prometheus-config-volume
mountPath: /etc/prometheus/
# PVC mounting point inside a Prometheus container
- name: prometheus-persistent-volume-claim
mountPath: /prometheus/
Loki Deployment:
# loki-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: loki-deployment
spec:
replicas: 1
selector:
matchLabels:
component: loki
template:
metadata:
labels:
component: loki
spec:
volumes:
- name: loki-config-volume
configMap:
name: loki-config
- name: loki-rules-config-volume
configMap:
name: loki-rules-config
- name: loki-persistent-volume-claim
persistentVolumeClaim:
claimName: loki-persistent-volume-claim
containers:
- name: loki
image: grafana/loki
args:
- "--config.file=/etc/loki/loki.yaml"
ports:
- containerPort: 3100
volumeMounts:
- name: loki-config-volume
mountPath: /etc/loki/
- name: loki-rules-config-volume
mountPath: /etc/loki/rules/fake
- name: loki-persistent-volume-claim
mountPath: /loki/
Grafana Deployment:
# grafana-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana-deployment
spec:
replicas: 1
selector:
matchLabels:
component: grafana
template:
metadata:
labels:
component: grafana
spec:
volumes:
- name: grafana-config-datasources-volume
configMap:
name: grafana-config-datasources
- name: grafana-persistent-volume-claim
persistentVolumeClaim:
claimName: grafana-persistent-volume-claim
containers:
- name: grafana
image: grafana/grafana
ports:
- containerPort: 3000
volumeMounts:
- name: grafana-config-datasources-volume
mountPath: /etc/grafana/provisioning/datasources
readOnly: false
- name: grafana-persistent-volume-claim
mountPath: /var/lib/grafana
ClusterIP Service
Why use Services? The IP address of the Pod object is assigned automatically. If you delete the Pod and create it again, the address may change. The Service object with the coredns solves this problem and allows you to access any Pod by the name of the Service object.
What about ClusterIP and NodePort objects? The NodePort object is used to forward ports to the Pod for access both outside (outside the cluster) and inside the cluster. This object is not usually used in production clusters. The ClusterIP object is used to link the Deployment object with other objects in the cluster. First of all, it allows to transfer incoming traffic to the Pods inside the Deployment object. If incoming traffic is not needed, you can only use Deployment object without Service NodePort or ClusterIP objects.
And here are my ClusterIP objects with comments:
Prometheus ClusterIP:
# prometheus-cluster-ip-service.yaml
apiVersion: v1
kind: Service
metadata:
name: prometheus-cluster-ip-service
spec:
type: ClusterIP
selector:
# label for communication with the Deployment object
component: prometheus
ports:
# port inside the container
- port: 9090
# port outside the container
targetPort: 9090
Loki ClusterIP:
# loki-cluster-ip-service.yaml
apiVersion: v1
kind: Service
metadata:
name: loki-cluster-ip-service
spec:
type: ClusterIP
selector:
component: loki
ports:
- port: 3100
targetPort: 3100
Grafana ClusterIP:
# grafana-cluster-ip-service.yaml
apiVersion: v1
kind: Service
metadata:
name: grafana-cluster-ip-service
spec:
type: ClusterIP
selector:
component: grafana
ports:
- port: 3000
targetPort: 3000
Ingress
I’ll use github.com/kubernetes/ingress-nginx - community led project as an entry point to the cluster. Probably, it can be called best practice. If the number of Pod replicas in the Deployment object is > 1, ingress-nginx will provide traffic balancing between them. My case is 1 Pod replica in each Deployment, so the main task of ingress here will be routing of user traffic.
# ingress-service.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-service
annotations:
kubernetes.io/ingress.class: 'nginx'
nginx.ingress.kubernetes.io/use-regex: 'true'
spec:
rules:
- http:
paths:
# link with /prometheus will be addressed to prometheus ClusterIP
# for example, http://minikube_ip/prometheus/graph
- path: /(prometheus.*)
pathType: Prefix
backend:
service:
name: prometheus-cluster-ip-service
port:
number: 9090
# link with /loki will be addressed to loki ClusterIP
# for example, http://minikube_ip/loki/api/v1/status/buildinfo
- path: /(loki.*)
pathType: Prefix
backend:
service:
name: loki-cluster-ip-service
port:
number: 3100
# any other links will be addressed to grafana ClusterIP
# for example, http://minikube_ip
- path: /(.*)
pathType: Prefix
backend:
service:
name: grafana-cluster-ip-service
port:
number: 3000
Apply and check Kubernetes cluster
Apply configuration
root@devbox:~/Projects/k8s$ ls
grafana ingress-service.yaml loki prometheus
root@devbox:~/Projects/k8s$ kubectl apply -f prometheus
service/prometheus-cluster-ip-service created
configmap/prometheus-config created
deployment.apps/prometheus-deployment created
persistentvolumeclaim/prometheus-persistent-volume-claim created
root@devbox:~/Projects/k8s$ kubectl apply -f loki
service/loki-cluster-ip-service created
configmap/loki-config created
deployment.apps/loki-deployment created
persistentvolumeclaim/loki-persistent-volume-claim created
configmap/loki-rules-config created
root@devbox:~/Projects/k8s$ kubectl apply -f grafana
service/grafana-cluster-ip-service created
configmap/grafana-config-datasources created
deployment.apps/grafana-deployment configured
persistentvolumeclaim/grafana-persistent-volume-claim created
root@devbox:~/Projects/k8s$ kubectl apply -f .
ingress.networking.k8s.io/ingress-service created
Check the availability of services
Because the cluster is on a minikube VM, then to access to services from outside the cluster you need to use the minikube VM ip:
root@devbox:~/Projects/k8s$ minikube ip
192.168.49.2
http routing is configured on Ingress. All links containing /(prometheus.*) and /(loki.*), will be addressed to the corresponding prometheus and loki ClusterIP services (ports 9090 for prometheus and 3100 for loki), and everything else, /(.*) - will be addressed to grafana ClusterIP (port 3000).
At the same time, each service must wait for a request along the appropriate path. For prometheus, this is implemented by the argument when starting the container - --web.external-url=https://localhost:9090/prometheus/, for loki, you need to define the path_prefix directive (when defined, the given prefix will be present in front of the endpoint paths) in ConfigMap and then, for example, path https://localhost:3100/loki/api/v1/status/buildinfo will be active. And for grafana, the default settings are used.
Checking accessibility from the browser:
# Prometheus
https://192.168.49.2/prometheus
# Loki
https://192.168.49.2/loki/api/v1/status/buildinfo
# Grafana
https://192.168.49.2
# Grafana datasources
https://192.168.49.2/datasources
Debugging
To debug the http services inside the Kubernetes cluster, it is useful to have a Pod with curl on board. I run such a Pod:
root@devbox:~/Projects/k8s$ kubectl run curlpod --image=curlimages/curl
For example, to check any changes in the Loki configuration bypassing Ingress, you can:
find out the ClusterIP ip for Loki:
root@devbox:~/Projects/k8s$ kubectl get service -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
grafana-cluster-ip-service ClusterIP 10.99.166.87 <none> 3000/TCP 69d component=grafana
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 126d <none>
loki-cluster-ip-service ClusterIP 10.100.46.66 <none> 3100/TCP 61d component=loki
prometheus-cluster-ip-service ClusterIP 10.107.49.254 <none> 9090/TCP 69d component=prometheus
open sh in curlpod:
root@devbox:~/Projects/k8s$ kubectl get pod
NAME READY STATUS RESTARTS AGE
curlpod 0/1 Completed 0 22m
grafana-deployment-5d8ccc6d46-kzw7j 1/1 Running 8 (32h ago) 45d
loki-deployment-567bc6d974-dvtl5 1/1 Running 13 (30h ago) 33d
prometheus-deployment-7b4d56c8bc-6tc2d 1/1 Running 3 (30h ago) 15d
root@devbox:~/Projects/k8s$ kubectl exec -it curlpod -- sh
/ $
check Loki ClusterIP DNS name via Kubernetes coredns from running curlpod:
/ $ nslookup 10.100.46.66
Server: 10.96.0.10
Address: 10.96.0.10:53
66.46.100.10.in-addr.arpa name = loki-cluster-ip-service.default.svc.cluster.local
send GET with curl from curlpod:
/ $ curl http://loki-cluster-ip-service.default.svc.cluster.local:3100/metrics
...
ring_member_tokens_to_own{name="compactor"} 1
ring_member_tokens_to_own{name="scheduler"} 1
Logs
To debug events inside the Pod, you can view the log, for example:
root@devbox:~/Projects/k8s$ kubectl get pod
NAME READY STATUS RESTARTS AGE
curlpod 1/1 Running 1 (17m ago) 39m
grafana-deployment-5d8ccc6d46-kzw7j 1/1 Running 8 (32h ago) 45d
loki-deployment-567bc6d974-dvtl5 1/1 Running 13 (30h ago) 33d
prometheus-deployment-7b4d56c8bc-6tc2d 1/1 Running 3 (30h ago) 15d
root@devbox:~/Projects/k8s$ kubectl logs loki-deployment-567bc6d974-dvtl5
...
For Pod, everything is simple. But how to view events on Ingress?
find the ingress-nginx-controller Pod and namespace:
root@devbox:~$ kubectl get pod --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
default curlpod 1/1 Running 1 (28m ago) 50m
default grafana-deployment-5d8ccc6d46-kzw7j 1/1 Running 8 (32h ago) 45d
default loki-deployment-567bc6d974-dvtl5 1/1 Running 13 (30h ago) 33d
default prometheus-deployment-7b4d56c8bc-6tc2d 1/1 Running 3 (30h ago) 15d
ingress-nginx ingress-nginx-admission-create-qvcrr 0/1 Completed 0 73d
ingress-nginx ingress-nginx-admission-patch-rp9pc 0/1 Completed 1 73d
ingress-nginx ingress-nginx-controller-5959f988fd-ptglc 1/1 Running 35 (30h ago) 73d
kube-system coredns-565d847f94-5ph98 1/1 Running 30 (32h ago) 126d
kube-system etcd-minikube 1/1 Running 30 (32h ago) 126d
kube-system kube-apiserver-minikube 1/1 Running 30 (32h ago) 126d
kube-system kube-controller-manager-minikube 1/1 Running 30 (30h ago) 126d
kube-system kube-proxy-rzndh 1/1 Running 29 (30h ago) 126d
kube-system kube-scheduler-minikube 1/1 Running 30 (30h ago) 126d
kube-system storage-provisioner 1/1 Running 107 (30h ago) 126d
check the log in the found Pod and namespace:
root@devbox:~$ kubectl logs -n ingress-nginx ingress-nginx-controller-5959f988fd-ptglc
...
Ingress troubleshooting is described here