Elastic stack. Part 2. Simple Elasticsearch cluster
All pages
| Name | Summary |
|---|---|
| Elastic stack. Part 1. Overview | Overview of the Elastic stack |
| Elastic stack. Part 2. Simple Elasticsearch cluster | Let’s build a simple Elasticsearch cluster from scratch |
Basic Installation
We have 3 data centers, each with 2 virtual machines on CentOS. The first machine will be Elasticsearch data + master node, second - Elasticsearch coordinator node + Logstash. And we will install and configure Kibana on one of the machines with Elasticsearch coordinator node. Yes, without redundancy and any http load balancer. Let’s take a look at the diagram and our cluster design for this article:

Here we use the minimum hardware requirements for the machines from the documentation, except for disks. In our case, data nodes has 2 disks with 100 + 500Gb, and coordinator nodes has 2 disks with 50 + 50Gb.
At first, configure the network on each machine:
- disable NetworkManager. I don’t like this tool, it cause me a lot of pain
chkonfig NetworkManager off
# or
systemctl disable NetworkManager.service
- configure interface:
vi /etc/sysconfig/network-script/ifcfg-ens192
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=yes
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens192
UUID=bbf8d69a-2e11-4121-a7c0-5f5b7c9fef0b
DEVICE=ens192
ONBOOT=yes
# node IPADDR accroding to the diagram
IPADDR=10.1.1.1
PREFIX=24
# node GATEWAY
GATEWAY=10.1.1.254
# node DNS
DNS1=8.8.8.8
IPV6_PRIVACY=no
NM_CONTROLLED=no
Now let’s think about, how to scale disks when increasing logs. There is LVM for this. On CentOS, the root partition has already been added to centos Volume group and to Logical volume as /dev/centos/root. LVM makes it easy to add and expand disk volumes without unmounting file systyems and stopping applications.
So, in our case, on data + master nodes the /dev/centos/root LVM is 100Gb (and 500Gb disk space, outside root LVM), and on the coordinator nodes is 50Gb (and 50Gb disk space, outside root LVM). Let’s add free disk space on each node to the /dev/centos/root LVM.
As instance:
# check all physical disks
fdisk -l
# see our 500Gb or 50Gb disk as /dev/sdb
# mark the disk for LVM
pvcreate /dev/sdb
# check all physical volumes (now there are 2 of them)
pvdisplay
# CentOS has LVM already. Let's add our new pv (/dev/sdb) to Volume group (vg) and Logical volume (lv)
# check Volume groups
vgdisplay
# see centos Volume group
# add /dev/sdb to centos vg
vgextend centos /dev/sdb
# check Volume group again
vgdisplay
# check Logical volumes
lvdisplay
# add 100% free disk capacity to Logical volume (lv) /dev/centos/root
lvextend -l 100%FREE /dev/centos/root
# check Logical volume again
lvdisplay
# check disk space structure
lsblk
# check disk usage
df -h
# and we see old disk size
# let's update disk size with new lvm
# for xfs file system
xfs_growfs /dev/centos/root
# for ext2/ext3/ext4
resize2fs /dev/centos/root
# for reiserfs
resize_reiserfs /dev/centos/root
# check /etc/fstab
# for example, for xfs file system
/dev/mapper/centos-root / xfs defaults 0 0
# mount all
mount -a
# check Logical volume and disk structure again
lvdisplay
# ...
# --- Logical volume ---
# LV Path /dev/centos/root
# ...
# LV Size <595,12 GiB
lsblk
# ...
# └─sda2 8:2 0 99G 0 part
# ├─centos-root 253:0 0 595,1G 0 lvm /
# sdb 8:16 0 500G 0 disk
# └─sdb1 8:17 0 500G 0 part
# └─centos-root 253:0 0 595,1G 0 lvm /
Network and disks are configured, lets configure hostnames and datetime on each node:
# configure datetime
yum install tzdata
timedatectl set-timezone Europe/Moscow
# sync time
yum install chrony
systemctl start chronyd
systemctl enable chronyd
systemctl status chronyd
timedatectl status
# configure hostname
# for data + master node
hostnamectl set-hostname elk-data-master-dc1
# for coordinator + logstash node
hostnamectl set-hostname elk-coordinator-dc1
Data writing and search requests
Of course, Elasticsearch cluster design is an individual thing. The node roles and their number, routing allocation settings and search request routing settings depend on the service architecture.
Let’s take a look at the general data storage scheme, in our case:
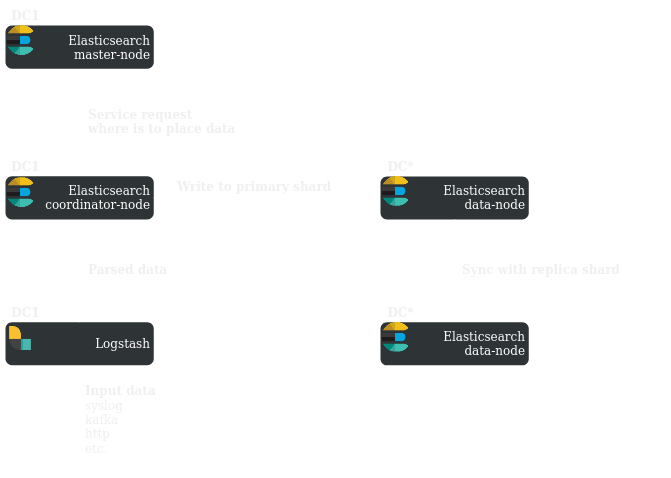
Depending on the shard allocation routing settings, the master node will suggest the coordinator node, on which data nodes to store data. By default, for version 7.x, 3 data nodes and 1 data index:
- 1 primary shard, 2 replica shards
- 1 shard for each data node
- see details in Part 1
Ok, it was about data writing, now let’s talk about user search requests:
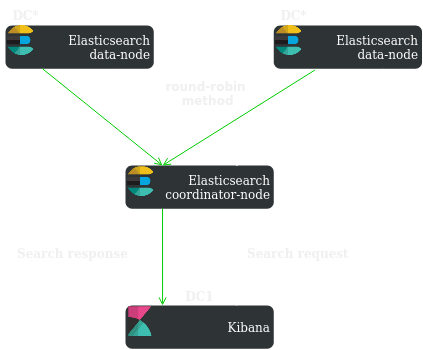
The coordinator node collects information from different data nodes depending on the search shard routing settings (by default, the round-robin mechanism is used) and then transmits it to the client.
Elasticsearch basic configuration
The preparatory work is over. Let’s perform the basic configuration of Elasticsearch nodes in data center 1 (dc1).
First, let’s configure the coordinator node, 10.1.1.2, elk-coordinator-dc1. The basic configuration of coordinator nodes in other data centers (dc2, dc3) is similar (except for names and ip addresses):
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
# about cluster name setting - https://www.elastic.co/guide/en/elasticsearch/reference/7.16/important-settings.html#cluster-name
#
cluster.name: elk-cluster
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
# about node name setting - https://www.elastic.co/guide/en/elasticsearch/reference/7.16/important-settings.html#node-name
#
node.name: elk-c-node-dc1
#
# Node roles
# Coordinator role = no role
# about node roles - https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-node.html
#
node.roles: [ ]
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
path.data: /var/lib/elasticsearch
#
# Path to log files:
#
path.logs: /var/log/elasticsearch
#
# ---------------------------------- Network -----------------------------------
#
# By default Elasticsearch is only accessible on localhost. Set a different
# address here to expose this node on the network:
#
# about network host setting - https://www.elastic.co/guide/en/elasticsearch/reference/7.16/important-settings.html#network.host
#
network.host: [ _local_, 10.1.1.2 ]
#
# By default Elasticsearch listens for HTTP traffic on the first free port it
# finds starting at 9200. Set a specific HTTP port here:
#
http.port: 9200
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when this node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
# about discovery process - https://www.elastic.co/guide/en/elasticsearch/reference/7.16/important-settings.html#discovery-settings
#
discovery.seed_hosts: ["10.1.1.1", "10.1.2.1", "10.1.2.2", "10.1.3.1", "10.1.3.2"]
#
But if we look at the log, we will, probably, see the following there:
[root@elk-coordinator-dc1 ~]# tail -f /var/log/elasticsearch/elk-cluster.log
Caused by: java.lang.IllegalStateException: node does not have the data and master roles but has index metadata: [/var/lib/elasticsearch/nodes/0/indices/Ghncl736QeCae6Rg9art2A/_state, /var/lib/elasticsearch/nodes/0/indices/QIQTgTv7T_Sen7zSQphRCQ/_state, /var/lib/elasticsearch/nodes/0/indices/HD0zPBvSQTC5r56kVAeyZg/_state, /var/lib/elasticsearch/nodes/0/indices/xbqM9ibUTceqAW6dJKrLxw/_state, /var/lib/elasticsearch/nodes/0/indices/0AR_DcO0S62Cvz515wHGIw/_state, /var/lib/elasticsearch/nodes/0/indices/MAmQHLUVTdmT8nrZ3KA9wQ/_state, /var/lib/elasticsearch/nodes/0/indices/8U-eln9pTr2rZLdguJ2_Gg/_state, /var/lib/elasticsearch/nodes/0/indices/vg4r9DAKTe2NhujEJNodlw/_state]. Use 'elasticsearch-node repurpose' tool to clean up
It’s a little problem like this
And, as written, coordinator node does not have a master/data role, and we need to clean up unused shards:
[root@elk-coordinator-dc1 ~]# /usr/share/elasticsearch/bin/elasticsearch-node repurpose -v
...
Node successfully repurposed to no-master and no-data.
us
[root@elk-coordinator-dc1 ~]# systemctl restart elasticsearch
At second, let’s perform the basic configuration of data + master node, 10.1.1.1, elk-data-master-dc1. The basic configuration of data + master nodes in other data centers (dc2, dc3) is similar (just change the names and ip addresses):
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
# about cluster name setting - https://www.elastic.co/guide/en/elasticsearch/reference/7.16/important-settings.html#cluster-name
#
cluster.name: elk-cluster
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
# about node name setting - https://www.elastic.co/guide/en/elasticsearch/reference/7.16/important-settings.html#node-name
#
node.name: elk-dm-node-dc1
#
# Node roles
# about node roles - https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-node.html
#
node.roles: [ data, master ]
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
path.data: /var/lib/elasticsearch
#
# Path to log files:
#
path.logs: /var/log/elasticsearch
#
# ---------------------------------- Network -----------------------------------
#
# By default Elasticsearch is only accessible on localhost. Set a different
# address here to expose this node on the network:
#
# about network host setting - https://www.elastic.co/guide/en/elasticsearch/reference/7.16/important-settings.html#network.host
#
network.host: [ _local_, 10.1.1.1 ]
#
# By default Elasticsearch listens for HTTP traffic on the first free port it
# finds starting at 9200. Set a specific HTTP port here:
#
http.port: 9200
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when this node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
# about discovery process - https://www.elastic.co/guide/en/elasticsearch/reference/7.16/important-settings.html#discovery-settings
#
discovery.seed_hosts: ["10.1.1.2", "10.1.2.1", "10.1.2.2", "10.1.3.1", "10.1.3.2"]
#
# Bootstrap the cluster using an initial set of master-eligible nodes:
#
# about cluster bootstrapping - https://www.elastic.co/guide/en/elasticsearch/reference/7.16/important-settings.html#initial_master_nodes
#
cluster.initial_master_nodes: ["10.1.1.1", "10.1.2.1", "10.1.3.1"]
#
# For more information, consult the discovery and cluster formation module documentation.
#
After we have configured all nodes, it’s time to check the status of the Elasticsearch cluster like this with curl from any Elasticsearch node(data-master node is just example here):
[root@elk-data-master-dc1 ~]# curl 10.1.1.1:9200/_cat/nodes?v
# or
[root@elk-data-master-dc1 ~]# curl localhost:9200/_cat/nodes?v
[root@elk-data-master-dc1 ~]# curl -XGET '10.1.1.1:9200/_cluster/health?pretty'
# or
[root@elk-data-master-dc1 ~]# curl -XGET 'localhost:9200/_cluster/health?pretty'
[root@elk-data-master-dc1 ~]# curl -XGET '10.1.1.1:9200/_cluster/state?pretty'
# or curl to file (there may be a lot of information here)
[root@elk-data-master-dc1 ~]# curl -XGET '10.1.1.1:9200/_cluster/state?pretty' > elk-cluster.txt
# or
[root@elk-data-master-dc1 ~]# curl -XGET 'localhost:9200/_cluster/state?pretty'
# or curl to file (there may be a lot of information here)
[root@elk-data-master-dc1 ~]# curl -XGET 'localhost:9200/_cluster/state?pretty' > elk-cluster.txt
For example, the output of the first command (curl localhost:9200/_cat/nodes?v) should look like this:
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
10.1.1.1 34 95 6 0.08 0.13 0.11 dm - elk-dm-node-dc1
10.1.2.1 25 96 1 0.00 0.01 0.05 dm - elk-dm-node-dc2
10.1.3.2 34 98 1 0.01 0.05 0.05 - - elk-c-node-dc3
10.1.2.2 19 98 2 0.02 0.02 0.05 - - elk-c-node-dc2
10.1.1.2 5 98 7 0.06 0.13 0.21 - - elk-c-node-dc1
10.1.3.1 79 97 3 0.22 0.06 0.06 dm * elk-dm-node-dc3
But, perhaps, you, like me, do not have such a beautiful output and have some problems with coordinating and master+data nodes :) Let’s look at at the logs and try to figure it out. First, on coordinator node:
[root@elk-coordinator-dc1 ~]# tail -f /var/log/elasticsearch/elk-cluster.log
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:946) ~[?:?]
at io.netty.channel.socket.nio.NioSocketChannel.doFinishConnect(NioSocketChannel.java:330) ~[?:?]
at io.netty.channel.nio.AbstractNioChannel$AbstractNioUnsafe.finishConnect(AbstractNioChannel.java:334) ~[?:?]
... 7 more
[2021-10-19T12:07:57,076][WARN ][o.e.c.c.ClusterFormationFailureHelper] [elk-c-node-dc1] master not discovered yet: have discovered [{elk-c-node-dc1}{bvxibotsRbKZGqEZWlsHwQ}{roCnFWypTtWGbXTfUwmkqw}{10.1.1.2}{10.1.1.2:9300}]; discovery will continue using [10.1.1.1:9300, 10.1.2.1:9300, 10.1.2.2:9300] from hosts providers and [{elk-dm-node-dc1}{REI3xb0BQ2CocawHiiWIyg}{JMnN_nQ5TEe7huYhkUZvvg}{10.1.1.1}{10.1.1.1:9300}{dm}] from last-known cluster state; node term 2, last-accepted version 58 in term 2
[2021-10-19T12:08:07,079][WARN ][o.e.c.c.ClusterFormationFailureHelper] [elk-c-node-dc1] master not discovered yet: have discovered [{elk-c-node-dc1}{bvxibotsRbKZGqEZWlsHwQ}{roCnFWypTtWGbXTfUwmkqw}{10.1.1.2}{10.1.1.2:9300}]; discovery will continue using [10.1.1.1:9300, 10.1.2.1:9300, 10.1.1.1:9300] from hosts providers and [{elk-dm-node-dc1}{REI3xb0BQ2CocawHiiWIyg}{JMnN_nQ5TEe7huYhkUZvvg}{10.1.1.1}{10.1.1.1:9300}{dm}] from last-known cluster state; node term 2, last-accepted version 58 in term 2
Let’s try to resolve it:
[root@elk-coordinator-dc1 ~]# systemctl restart elasticsearch
Yep, just restart it. Now you should see something like this:
# log after restart
# /var/log/elasticsearch/elk-cluster.log
[root@elk-coordinator-dc1 ~]# tail -f /var/log/elasticsearch/elk-cluster.log
[2021-10-19T13:38:42,304][INFO ][o.e.t.TransportService ] [elk-c-node-dc1] publish_address {10.1.1.2:9300}, bound_addresses {10.1.1.2:9300}
[2021-10-19T13:38:42,817][INFO ][o.e.b.BootstrapChecks ] [elk-c-node-dc1] bound or publishing to a non-loopback address, enforcing bootstrap checks
[2021-10-19T13:38:43,222][INFO ][o.e.c.s.ClusterApplierService] [elk-c-node-dc1] master node changed {previous [], current [{elk-dm-node-dc1}{REI3xb0BQ2CocawHiiWIyg}{8-C5S43HRbCX4KJbBz250g}{10.1.1.1}{10.1.1.1:9300}{dm}]}, added {elk-dm-node-dc1}{REI3xb0BQ2CocawHiiWIyg}{8-C5S43HRbCX4KJbBz250g}{10.1.1.1}{10.1.1.1:9300}{dm}, term: 3, version: 103, reason: ApplyCommitRequest{term=3, version=103, sourceNode={elk-dm-node-dc1}{REI3xb0BQ2CocawHiiWIyg}{8-C5S43HRbCX4KJbBz250g}{10.1.1.1}{10.1.1.1:9300}{dm}{xpack.installed=true, transform.node=false}}
[2021-10-19T13:38:43,522][INFO ][o.e.x.s.a.TokenService ] [elk-c-node-dc1] refresh keys
[2021-10-19T13:38:43,840][INFO ][o.e.x.s.a.TokenService ] [elk-c-node-dc1] refreshed keys
[2021-10-19T13:38:43,919][INFO ][o.e.l.LicenseService ] [elk-c-node-dc1] license [1247fe9b-deb2-45c8-9eff-7a20fc7b5f96] mode [basic] - valid
[2021-10-19T13:38:43,921][INFO ][o.e.x.s.s.SecurityStatusChangeListener] [elk-c-node-dc1] Active license is now [BASIC]; Security is disabled
[2021-10-19T13:38:43,924][WARN ][o.e.x.s.s.SecurityStatusChangeListener] [elk-c-node-dc1] Elasticsearch built-in security features are not enabled. Without authentication, your cluster could be accessible to anyone. See https://www.elastic.co/guide/en/elasticsearch/reference/7.15/security-minimal-setup.html to enable security.
[2021-10-19T13:38:43,948][INFO ][o.e.h.AbstractHttpServerTransport] [elk-c-node-dc1] publish_address {10.1.1.2:9200}, bound_addresses {10.1.1.2:9200}
[2021-10-19T13:38:43,949][INFO ][o.e.n.Node ] [elk-c-node-dc1] started
Second, on data+master nodes. If you, like me, configured nodes at different times, then some of them could form their own cluster with their own UUID. For example, my Elasticsearch nodes formed 3 clusters - one cluster in each datacenter. You can check it with curl localhost:9200/_cat/nodes?v command.
And, of course, this problem can be seen in /var/log/elasticsearch-elk-cluster.log - node can’t connect to cluster with UUID.
Usefull links on the topic:
- https://discuss.elastic.co/t/change-es-cluster-uuid/193092
- https://www.elastic.co/guide/en/elasticsearch/reference/current/node-tool.html#node-tool-detach-cluster
So, we can resolve this problem with elasticsearch-node tool (see last link above). elastcisearch-node tool has many modes and very useful for cluster control. For our example we need to recreate cluster with new UUID. Do it as in example:
# run command on first node
[root@elk-data-master-dc1 ~]# /usr/share/elasticsearch/bin/elasticsearch-node unsafe-bootstrap
...
Confirm [y/N] y
# now detach all nodes from the cluster with different UUID to cluster with new UUID on elk-dm-node-dc1
[root@elk-data-master-dc1 ~]# /usr/share/elasticsearch/elasticsearch-node detach-cluster
# check cluster state and nodes
[root@elk-data-master-dc1 ~]# curl localhost:9200/_cat/nodes?v
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
10.1.1.1 89 0 0.00 0.01 0.05 dm - elk-dm-node-dc1
10.1.2.1 88 91 2.39 2.53 2.52 - - elk-dm-node-dc2
10.1.3.2 79 2 0.00 0.01 0.05 dm * elk-c-node-dc3
10.1.2.2 95 94 2.76 2.64 2.70 - - elk-c-node-dc2
10.1.1.2 88 0 0.00 0.01 0.05 dm - elk-c-node-dc1
10.1.3.1 87 94 3.18 2.92 2.76 - - elk-dm-node-dc3
[root@elk-data-master-dc1 ~]# curl -XGET 'localhost:9200/_cluster/health?pretty'
{
"cluster_name" : "elk-cluster",
"status" : "red",
"timed_out" : false,
"number_of_nodes" : 6,
"number_of_data_nodes" : 3,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 16,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 0.0
}
This example can also help, if need to re-from a cluster, for example, several servers have failed.
elasticsearch-node tool can be usefull for many cases, when working with cluster (see link)
Ok, but now our Elasticsearch cluster status is red. I have UNASSIGNED system indecies. It’s the reason. Of course, you need to check /var/log/elasticsearch-elkcluster.log, at first. Btw, the same will happen, if you delete /var/lib/elasticsearch/nodes/0 index directory (yes, i did it, but don’t you do it). Let’s solve it:
# check all UNASSIGNED indecies
[root@elk-data-master-dc1 ~]# curl -XGET localhost:9200/_cat/shards?h=index,shard,prirep,state,unassigned.reason | grep UNASSIGNED
...
.geoip_databases 0 r UNASSIGNED
.geoip_databases 0 p UNASSIGNED
.ds-ilm-history-5-2021.10.19-000001 0 p UNASSIGNED
.ds-ilm-history-5-2021.10.19-000001 0 r UNASSIGNED
# check reason for UNASSIGNED status
[root@elk-data-master-dc1 ~]# curl -XGET localhost:9200/_cluster/allocation/explain?pretty
# delete all UNASSIGNED indecies
[root@elk-data-master-dc1 ~]# curl -XGET http://localhost:9200/_cat/shards | grep UNASSIGNED | awk {'print $1'} | xargs -i curl -XDELETE "http://localhost:9200/{}"
# but we can't delete .geoip and .ds-ilm-history indecies and data streams
# {"error":{"root_cause":[{"type":"illegal_argument_exception","reason":"Indices [.geoip_databases] use and access is reserved for system operations"}],"type":"illegal_argument_exception","reason":"Indices [.geoip_databases] use and access is reserved for system operations"},"status":400}{"error":{"root_cause":[{"type":"illegal_argument_exception","reason":"Indices [.geoip_databases] use and access is reserved for system operations"}],"type":"illegal_argument_exception","reason":"Indices [.geoip_databases] use and access is reserved for system operations"},"status":400}{"error":{"root_cause":[{"type":"illegal_argument_exception","reason":"index [.ds-ilm-history-5-2021.10.19-000001] is the write index for data stream [ilm-history-5] and cannot be deleted"}],"type":"illegal_argument_exception","reason":"index [.ds-ilm-history-5-2021.10.19-000001] is the write index for data stream [ilm-history-5] and cannot be deleted"},"status":400}{"error":{"root_cause":[{"type":"illegal_argument_exception","reason":"index [.ds-ilm-history-5-2021.10.19-000001] is the write index for data stream [ilm-history-5] and cannot be deleted"}],"type":"illegal_argument_exception","reason":"index [.ds-ilm-history-5-2021.10.19-000001] is the write index for data stream [ilm-history-5] and cannot be deleted"},"status":400}
# to delete .geoip_databases with CURL
# of course, curl can be used from any host.
[root@elk-coordinator-dc1 ~]# curl -XPUT "http://10.1.1.2:9200/_cluster/settings"
# or
[root@elk-coordinator-dc1 ~]# curl -XPUT localhost:9200/_cluster/settings
{
"persistent": {
"ingest.geoip.downloader.enabled": false
}
}
[root@elk-coordinator-dc1 ~]# curl -XPUT "http://10.1.1.2:9200/_cluster/settings"
# or
[root@elk-coordinator-dc1 ~]# curl -XPUT localhost:9200/_cluster/settings
{
"persistent": {
"ingest.geoip.downloader.enabled": true
}
}
# to delete .ds-ilm-history data_stream, we will configure Kibana in the next part of te article
# to delete .ds-ilm-history data_stream with Kibana interface:
Index Management - Data Streams - ilm-history - delete
# check cluster status
[root@elk-coordinator-dc1 ~]# curl -XGET 'localhost:9200/_cluster/health?pretty'
{
"cluster_name" : "elk-cluster",
"status" : "green",
...
All is fine. Nice.
Useful links to solve this problem:
- https://www.cyberithub.com/how-to-delete-elasticsearch-unassigned-shards/
- https://www.datadoghq.com/blog/elasticsearch-unassigned-shards/
- https://discuss.elastic.co/t/cluster-health-status-is-red/284320/3
- https://discuss.elastic.co/t/how-to-disable-geoip-usage-in-7-14-0/281076/13
- https://discuss.elastic.co/t/unassigned-ilm-history-shard-cluster-in-red-state/246970
- https://discuss.elastic.co/t/ilm-history-2-000001-unassigned-primary-shard-for-this-replica-is-not-yet-active/246978
- https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-delete-index.html
- https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-delete.html
- https://fabianlee.org/2018/10/02/elk-deleting-unassigned-shards-to-restore-cluster-health/
So, we have built an Elasticsearch cluster. Now, we will:
- configure the
Logstash, writesyslogparsers, usinggrokfilter, send parsed data toElasticsearchindecies andZabbixwithelasticsearchandzabbixoutput plugins - configure
Kibana, write Index Lifecycle Policies (ILM), see useful buttons - configure
Elasticsearchshard allocation routing
But, in the next part of the article.