Stupid legacy CI/CD
Introduction
To implement CI/CD your devices must be able to use CI/CD.
As instance, the config delivery can be using the config replace method or the available netconf actions (edit-config, copy-config, commit) that perform replace/merge/remove for both the entire configuration and part of it in the datastore(candidate, running). Such netconf capabilities as validate and rollback-on-error will help to validate the configuration. This is an important part of CI/CD process.
And what if your devies are super legacy, and they can’t do any of the above? The only option here is to devide the configuration into pieces(snmp, aaa, ntp, etc.) and create a single management scenario/script/tool to manage it. Although, the correct answer is not to suffer from bullshit, CI/CD is not for you… ;d
Although we are talking about legacy network devices, changing the usual approach to network management is good in any case. You can’t always click buttons in the CLI (or you can?) or accumulate an infinite scripts. You need a unified approach to network management. Why not to take the concept of “Network as Code (NaC)” and CI/CD as the basis for this. Yes, for the legacy network. Yes, it sounds like a joke or an initially bad idea. Well, well, so be it! But maybe the result and changing of the usual, routine approach to network management will have a positive impact and motivate you/your CLI lovers :)
Let’s start
All sources in this repository
I have a testing stand with huawei devices at hand, and it will be easier for me to use this as an example. But it doesn’t matter at all.
We will use source-control (git), source of truth (NetBox), CI/CD (Gitlab), coding (python3.8+ + Nornir framework), testing (pytest), templates (jinja2). But, at first, we will talk about data types. It’s a way to abstract our text configuration files. We will represent the text config pieces as YAML data. Let’s immediately look at an example of an YAML (it’s common.yaml file in git repository - ./dc-3/common.yaml) file describing SNMP configuration for a group of devices that refer to a common DC(dc-3 in example) or location and have common device role (access in example) in network design:
filter: "F(device_role__name__contains='access') & F(data__site__name__contains='dc-3')"
configs:
snmp:
params:
snmp_acl: ["2001", "2001"]
snmp_version: ["v2c v3"]
snmp_trap_address: ["10.1.2.3", "10.1.2.3"]
commands:
# compare configs
compare_script: ""
no_commands:
- []
- ["undo snmp-agent sys-info version {}"]
- ["undo snmp-agent target-host trap address udp-domain {} params securityname cipher snmp",
"undo snmp-agent target-host trap address udp-domain {} params securityname snmp"]
yes_commands:
- ["snmp-agent community read cipher snmp mib-view SNMP acl {}",
"snmp-agent group v3 snmp privacy read-view SNMP notify-view SNMP acl {}"]
- ["snmp-agent sys-info version {}"]
- ["snmp-agent target-host trap address udp-domain {} params securityname cipher snmp v2c",
"snmp-agent target-host trap address udp-domain {} params securityname snmp v3 privacy"]
# delete configs
delete_commands: ["undo snmp"]
# deploy commands (List with commands or path to task)
config_commands: "cmd_configure_snmp.py"
Let’s take in order:
filter- Nornir filter for group of devices. This filter is used only for groups.configs- here are parameters describing configuration pieces (snmp,aaa,ntp, anything)snmp- parameters describingsnmpconfig for group of devices.paramsandcommandsin this section describes thesnmpsettings.paramscan be changed and should be changed. This is our control mechanism.commandsdescribe 3 possible actions: changing parameter (compare_script,no_commandsandyes_commands), deletingsnmpconfiguration (delete_commands), and config (config_commands). Both commands list and scripts can be used ascommands. Next we’ll see how it works.
We can describe ntp, syslog or aaa configuration in configs, of course. It’s template.
Git repository and Source of Truth
Our YAML files are our Source of Truth. They should show the current state of the network. By changing the parameters in YAML file, we change the state of a network device or a group of network devices.
But what should the repository with YAMLs be like? There are many network devices, different vendors, different roles. And here is about the Source of Truth(SoT).
The Source of Truth is a starting point for all your network automation. Here you store all the necessary data about network devices. The Source of Truth is a structure of your network: devices are divided into types, roles, and linked to sites. You can always select the necessary group of devices by filtering these parameters.
If you Google it, then Ansible and Ansible inventory files will be a popular option here. This is the simplest option - to describe the network structure in the form of YAMLs. But this cannot be called a Source of Truth, it’s just an inventory that will allow you to have a minimum of data to connect to network devices.
So, such a Source of Truth for us will not be Asnible, but NetBox. I.e., the structure of our git repository = the structure of devices from NetBox. But why do we need to duplicate it, if we can store our configuration files in NetBox, it has a convenient thing - config context. This is true, but here’s the problem - there is no queue or versioning (it is very obvious, btw, but only as a NetBox plugin), which means that it is a bad idea to manage a network for a group of engineers using config context in NetBox. Therefore, we will manage it from our git repository, and repository structure will be correspond the structure of devices in the NetBox. Let’s look at an example:
$ tree
.
├── README.md
├── region-1
│ ├── common.yaml
│ ├── dc-1
│ │ └── common.yaml
│ ├── dc-2
│ │ └── common.yaml
│ ├── dc-3
│ │ ├── common.yaml
│ │ ├── device_1.yaml
│ │ ├── device_2.yaml
│ │ └── device_3.yaml
│ ├── dc-4
│ │ ├── common.yaml
│ │ ├── device_1.yaml
│ │ ├── device_2.yaml
│ │ └── device_3.yaml
│ └── dc-5
│ └── common.yaml
├── region-2
│ ├── common.yaml
│ ├── dc-6
│ │ ├── common.yaml
│ │ ├── device_1.yaml
│ │ ├── device_2.yaml
│ │ └── device_3.yaml
│ └── dc-7
│ ├── common.yaml
│ ├── device_1.yaml
│ ├── device_2.yaml
│ └── device_3.yaml
├── region-3
│ ├── common.yaml
│ ├── dc-8
│ │ ├── device_1.yaml
│ │ ├── device_2.yaml
│ │ ├── device_3.yaml
│ │ └── common.yaml
│ ├── dc-9
│ │ ├── common.yaml
│ │ ├── device_1.yaml
│ │ ├── device_2.yaml
│ │ └── device_3.yaml
│ └── dc-10
│ ├── common.yaml
│ ├── device_1.yaml
│ ├── device_2.yaml
│ └── device_3.yaml
└── common.yaml
Each directory has a common.yaml file, by changing the parameters of which, we manage at once a group of devices related to the location and described by the filter. You can always create another common_anything.yaml next to common.yaml describing any other device group. Here are the yaml describing individual devices (device_1.yaml, device_2.yaml, device_3.yaml), they do not need a filter parameter, the device name/file name is a filter already.
The repository structure should change along with the NetBox structure (sometimes we add new sites and devices, at least). But I would not like to complicate everything with the task of synchronization, but I would like to limit myself to a small script that will create or update the content of the repository. This, of course, is an individual thing, but I give an example (structure.py) for the directory tree above:
import os
import re
import pynetbox
from pynetbox.core.api import Api as api
def create_repo(nb: api, path: str, platform: str) -> None:
# create regions and sites
for obj in nb.dcim.sites.all():
if obj.region:
os.makedirs(f"{path}/{obj.region.slug}/{obj.slug}", exist_ok=True)
# create .yaml for regions, site, devices
for device in nb.dcim.devices.filter(platform=platform):
site_name = device.site.slug
for root, dirs, _ in os.walk(path):
# create common.yaml files for regions and sites
if ".git" not in root and not os.path.exists(f"{root}/common.yaml"):
with open(f"{root}/common.yaml", "w"):
pass
# create {device.name}.json for devices
if site_name in dirs:
if not os.path.exists(f"{root}/{site_name}/{device.name}.yaml"):
with open(f"{root}/{site_name}/{device.name}.yaml", "w"):
pass
# alternate, but not for mac
# os.mknod(f"{root}/{site_name}/{device.name}.yaml")
if __name__ == "__main__":
create_repo(
# change your_netbox_domain and your_netbox_token
nb=pynetbox.api(
"http://your_netbox_domain", token="your_netbox_token"
),
path=os.getcwd(),
# change the your_device_platform
platform="your_device_platform",
)
Gitlab and .gitlab-ci.yaml
It’s time to think about how we can organize the versioning of configurations and pipeline delivery. At the very beginning, we said that we have a legacy network, and we can’t build a pipeline using netconf. By the way, it could look like this (with the support of the corresponding netconf capabilities): lock candidate datastore > netconf edit config action to candidate datastore > validate/rollback-on-error (for tests pipeline stage) > commit > unlock candidate datastore. In this case, we could form the configuration only based on the last commit, and it would really be similar to NaC. We will have to look at the git diff between the last two commits, take our YAMLs from it, pass them to the handler, which will compare the parameters and make the necessary configuration. We will write a simple handler in python. And we will describe other things with a pipeline:
stages:
- update_cache
- compare_commits
- tests
- run
# we use single runner "docker0"
default:
tags:
- docker0
cache:
key: ${CI_COMMIT_REF_SLUG}
paths:
- venv
- .cache/pip
update_cache:
image: python:3.8-slim-buster
before_script:
- ''
stage: update_cache
script:
- pip install virtualenv
- virtualenv venv
- source venv/bin/activate
- pip install --upgrade pip
- pip install pytest
- pip install pydantic
- pip install nornir-cli
only:
- schedules
compare_commits:
stage: compare_commits
script:
- git checkout HEAD~1
- mkdir -p previous
- git diff --name-only origin/master
- cp --parents $(git diff --name-only origin/master | sed '/.py\|.gitlab/d') previous
- ls previous
artifacts:
paths:
- previous
except:
- schedules
tests:
stage: tests
image: python:3.8-buster
script:
- source venv/bin/activate
- echo "START SOME TESTS"
- pytest --tb=short --disable-warnings -s
except:
- schedules
run:
image: python:3.8-buster
before_script:
- source venv/bin/activate
needs: ["tests"]
stage: run
script:
- python stupid_ci.py
when: manual
allow_failure: false
except:
- schedules
One of the jobs (update_cache), is performed by the schedule only, the others are not Therefore, we create a schedule for this job with Gitlab interface. CI/CD - Schedules - Custom - 0 6 * * *. This is just example, choose any time.
Let’s analyze it by stages:
update cache. We will perform this stage according to a schedule in order to speed up the pipeline and not be distracted by what needs to be done just once, and then follow the updates. Here we install and update the necessary python packages in a virtual environment with python 3.8compare commit. Here we dig out the YAMLs in which we changed the parameters (between the previous and last commit). If the YAML has changed, it means that the configuration on the device or device group has changed. Create thepreviousdirectory and copy our YAMLs from the previous commit to it. We transfer them to the following stages as artifactstests. The only source of truth and up-to-date configuration for us is our YAMLs. If some of them have changed, then it probably have to first check how these YAML’s of the previous commit correspond to the current state of the network. If something does not match, we consider the tests not passed, and we stop the pipeline on this and bring the network to the desired state. You can always run the tests againrun. If the tests are successful, then we pass the control to the python handler, which will form a configuration for the desired block of parameters or execute the required set of commands or script. We will run this stage manually, so we have more control. Let’s look at the handler, it is located in the filestupid_ci.py
YAML Handler
What should the handler be like? The handler should perform the network transition from one state to another painlessly. Hmm, well, as much as it is possible in our conditions, because our network initially can’t do this. What do we mean by the transition from one state to another? This are:
- when changing all parameters in YAML to empty, delete the part of configuration (as instance, snmp configuration) on the device/device group completely
- when creating a new configuration block/part of configuration (as instance, snmp configuration) or filling in all parameters in YAML (all parameters were empty), configure the part of configuration/configuration block (as instance, snmp configuration) on the device/device group from scratch
- when changing parameters in YAML from one to another, change the parameters of the part of configuration/ configuration block (as instance, snmp configuration) on the device/device group. For the example with snmp, this is
snmp_acl,snmp_version,snmp_trap_address.
That is, the difference in the parameters in our YAMLs forces the handler to perform the necessary action.
Let’s try to implement this in the form of a simple dataclass, in which we will describe each action with the appropriate method. Why the dataclass? Here is because pydantic python module + type annotations can perform validation of YAML input parameters. This is a cool option - we can check our YAML parameters, this is what we plan to input manually.
The dataclass implements 3 methods in accordance with above actions:
deleteconfigcompare
And our YAML handler
If to open the YAML example, we can see the format of the input data for each of the methods. Each method accepts either a list of commands or a string with the script name as input. If delete_commands and config_commands look clear, then compare needs to be explained. compare execute the script specified in compare_script parameter, and if it’s empty, it will try to make a configuration from lists of strings, where no_commands are lists of strings for deleting old parameters, yes_commands are lists of strings for setting new parameters. For example:
old parameters:
configs:
snmp:
params:
snmp_acl: []
snmp_version: []
snmp_trap_address: ["10.1.2.3", "10.1.2.3"]
new parameters:
configs:
snmp:
params:
snmp_acl: ["2001", "2001"]
snmp_version: ["v2c v3"]
snmp_trap_address: []
snmp:
snmp-agent community read cipher snmp_community mib-view SNMP acl 2001
snmp-agent group v3 snmp privacy read-view SNMP notify-view SNMP acl 2001
snmp-agent sys-info version v2c v3
undo snmp-agent target-host trap address udp-domain 10.1.2.3 params securityname cipher snmp
undo snmp-agent target-host trap address udp-domain 10.1.2.3 params securityname snmp
The deploy method apply the resulting configuration to the device/device group defined by the filter.
What else about YAML Handler
We put the login/password for connecting to devices in the system variables. For Gitlab - Settings, CI/CD, Variables. Create DC_USERNAME and DC_PASSWORD.
Also, this is true for save commands - apply SAVE system variable or change SAVE global variable in stupid_ci.py
config.yaml
We use nornir_netbox plugin as an Inventory for Nornir, so we store all the parameters in config.yaml. You nedd to add your connection parameters to config.yaml in git repo root directory.
Example of script
To configure snmp from scratch, we use the script cmd_configure_snmp.py. This is Nornir script. The function is cli always and ctx parameter is an Nornir object.
Why to use a script? For example, if some parameters are unique for each device from the group, and we can’t describe them in YAML as general. Yes, you can describe it for each device separately, but this is too much…
Tests
We will test the network for compliance with the current state. To do this, we need to compare the parameters from YAML with the parameters on the devices. If any of the parameters do not match, the test will not pass. This means that the configuration is not correct. Fix it and start test manually.
In our case, snmp test is snmp_test.py.
And the job that launched the failed test will look like this:
$ pytest --tb=short --disable-warnings -s
============================= test session starts ==============================
platform linux -- Python 3.8.10, pytest-6.2.4, py-1.10.0, pluggy-0.13.1
rootdir: /builds/user/test
Start testing
collected 3 items
test_snmp.py FFF
=================================== FAILURES ===================================
______ test_snmp[device_dict0-device_1-cur_dict0] ______
test_snmp.py:81: in test_snmp
assert cur_dict == device_dict, f"TESTING FAILED on {host}"
E AssertionError: TESTING FAILED on device_1
E assert {'snmp_acl': ...': ['v2c v3']} == {'snmp_acl': ...': ['v2c v3']}
E Omitting 2 identical items, use -vv to show
E Differing items:
E {'snmp_trap_address': ['10.1.2.3', '10.1.2.3']} != {'snmp_trap_address': []}
E Use -v to get the full diff
________ test_snmp[device_dict1-device_2-cur_dict1] ________
test_snmp.py:81: in test_snmp
assert cur_dict == device_dict, f"TESTING FAILED on {host}"
E AssertionError: TESTING FAILED on device_2
E assert {'snmp_acl': ...': ['v2c v3']} == {'snmp_acl': ...': ['v2c v3']}
E Omitting 2 identical items, use -vv to show
E Differing items:
E {'snmp_trap_address': ['10.1.2.3', '10.1.2.3']} != {'snmp_trap_address': []}
E Use -v to get the full diff
______ test_snmp[device_dict2-device_3-cur_dict2] ______
test_snmp.py:81: in test_snmp
assert cur_dict == device_dict, f"TESTING FAILED on {host}"
E AssertionError: TESTING FAILED on device_3
E assert {'snmp_acl': ...': ['v2c v3']} == {'snmp_acl': ...': ['v2c v3']}
E Omitting 2 identical items, use -vv to show
E Differing items:
E {'snmp_trap_address': ['10.1.2.3', '10.1.2.3']} != {'snmp_trap_address': []}
E Use -v to get the full diff
=========================== short test summary info ============================
FAILED test_snmp.py::test_snmp[device_dict0-device_1-cur_dict0]
FAILED test_snmp.py::test_snmp[device_dict1-device_2-cur_dict1]
FAILED test_snmp.py::test_snmp[device_dict2-device_3-cur_dict2]
================== 3 failed, 1 warning in 26.71s (0:00:26) ==================
Our pipeline with failed tests:
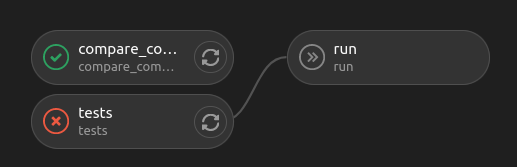
The deploy stage is started strictly manually, after the all tests have passed.
Conclusion
What do we need to, for example, add an ntp configuration to our pipeline:
- add parameters to YAML by analogy with snmp:
filter: "F(device_role__name__contains='access') & F(data__site__name__contains='dc-3')"
configs:
snmp:
params:
snmp_acl: ["2001", "2001"]
snmp_version: ["v2c v3"]
snmp_trap_address: ["10.1.2.3", "10.1.2.3"]
commands:
# compare configs
compare_script: ""
no_commands:
- []
- ["undo snmp-agent sys-info version {}"]
- ["undo snmp-agent target-host trap address udp-domain {} params securityname cipher snmp",
"undo snmp-agent target-host trap address udp-domain {} params securityname snmp"]
yes_commands:
- ["snmp-agent community read cipher snmp mib-view SNMP acl {}",
"snmp-agent group v3 snmp privacy read-view SNMP notify-view SNMP acl {}"]
- ["snmp-agent sys-info version {}"]
- ["snmp-agent target-host trap address udp-domain {} params securityname cipher snmp v2c",
"snmp-agent target-host trap address udp-domain {} params securityname snmp v3 privacy"]
# delete configs
delete_commands: ["undo snmp"]
# deploy commands (List with commands or path to task)
config_commands: "cmd_configure_snmp.py"
ntp:
params:
ntp_server: ["10.1.1.1"]
commands:
# compare configs
compare_script: ""
no_commands:
- []
- ["undo ntp-service unicast-server {}"]
yes_commands:
- ["ntp-service unicast-server {}"]
# delete configs
delete_commands: ["undo ntp-service unicast-server {}"]
# deploy commands (List with commands or path to task)
config_commands: ["ntp-service unicast-server {}"]
- write a test by analogy with
test_snmp.py. This is a template.
That is all. Any configuration can be described in this way.
And what else… I don’t want to waste time arguing about this, and I don’t advise you. Do not stand still and enjoy your work!